
 Verlauf
Verlauf

 Alle Kapitel anzeigen
Alle Kapitel anzeigen
LZW steht für Lempel-Ziv-Welch und ist einer der häufigsten Kompressionsalgorithmen für die Datenkompression bei Grafikformaten. LZW ist ein verlustfreier und symmetrischer (= Kodierung und Dekodierung sind gleich schnell) Algorithmus, der in folgenden Formaten genutzt wird:
- GIF
- TIFF (optional)
- PostScript Level II
- JPEG (optional)
Weiters liegt LZW dem Packprogramm "compress" und "zip" zugrunde.
LZW kann auf jede Form von digitalen Daten angewendet werden, sowohl auf Text- als auch auf Bilddaten. LZW speichert die komprimierten Daten in Byte-Form ab, wodurch eine Plattformunabhängigkeit erreicht wird.
Der LZW-Algorithmus basiert auf der Idee, dass sich in einer Wertefolge bestimmte Teilfolgen wiederholen. Er konstruiert ein Datenlexikon (= data dictonary) aller unkomprimierten Informationen. Der Datenstrom wird auf Muster (= substrings) untersucht und entwickelt daraus die Einträge für das Lexikon. Die Muster werden gemeinsam mit einer Kodierung (= code) im Lexikon gespeichert. Taucht in einem Datenstrom ein bereits im Lexikon gespeichertes Muster auf, so wird die vorhandene Kodierung in den komprimierten Datenstrom geschrieben. Da die Kodierung physikalisch kleiner ist als das Muster, das es repräsentiert, wird eine Datenkompression erreicht.
Eine Besonderheit des LZW-Algorithmus ist, dass das Lexikon nicht mitgespeichert wird, wodurch noch mal Speicherplatz gespart werden kann.
Das Kernstück dieses Algorithmus ist das Lexikon. Da das Lexikon ständig und vor allem schnell durchsucht werden muss, wird das Lexikon nicht sequenziell, also der Reihe nach, sondern mittels eines Hash-Algorithmus durchsucht. Ein Hash-Alogorithmus bildet die Werte auf eine wesentlich kleinere Zielmenge ab und verringert somit die Suchzeit. Weiters muss darauf geachtet werden, dass kein Überlauf im Lexikon auftritt.
Abraham Lempel und Jacob Ziv, zwei israelische Forscher, veröffentlichten 1977 in einem Magazin des IEEE (Institute of Electrical and Electronics Engineers) einen Algorithmus mit dem Namen LZ77. Während Ziv für die Idee und die theoretischen Grundlagen verantwortlich war, beschäftigte sich Lempel mit der Programmstruktur.
Dieser Algorithmus war einfach konzeptioniert und hätte schon vor 1977 implementiert werden können. Allerdings hatten die bisherigen Bemühungen in die Verbesserung der Huffman-Codierung die Entwicklung eines solchen Algorithmuses verhindert. Mit LZ77 ist die Welt der Datenkompression um die Philosophie des adaptiven Lexikons erweitert worden.
LZ77 und der ein Jahr später herausgebrachte Version LZ78 sind die Grundlage für die gesamte Familie der LZ-Algorithmen. Durch die Anpassung des ursprünglichen Algorithmus an spezielle Anforderungen (Kompression von Bild und Text etc.) besteht die LZ-Familie heute aus 4 Varianten.
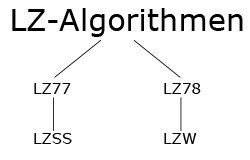
Übersicht LZ-Familie
Während LZSS eine Weiterentwicklung von LZ77 darstellt, ist LZW die Weiterentwicklung von LZ78.
Als Ausgangsbasis für die Kodierung erhält der Algorithmus einen Datenstrom und ein initialisiertes Lexikon (im Falle eines Textes wird das Lexikon mit 256 Einträgen initialisiert).
LZW verwendet bei der Kodierung einen Buffer (Zwischenspeicher) um sich die neuen Einträge für das Lexikon zusammenzubauen. Am Anfang ist der Buffer leer.
Der Datenstrom wird nun Zeichen für Zeichen eingelesen.
Sind die Zeichen des Buffers + Input (eingelesenes Zeichen) bereits im Lexikon vorhanden, so wird der Input am Ende der Zeichenkette im Buffer angefügt.
Ist die Zeichenkette des Buffers + Input (eingelesenes Zeichen) noch nicht im Lexikon vorhanden, so wird der "Code" der Zeichenkette des Buffers ausgegeben und das Lexikon um einen Eintrag (Zeichenkette des Buffers +Input) erweitert. Anschließend wird der Buffer auf den Input gesetzt.
Ist das Ende des Datenstroms erreicht, d.h. es sind keine weiteren Zeichen zum Einlesen mehr vorhanden, dann wird der "Code" der Zeichenkette des Buffers ausgegeben.
Ist noch ein (oder auch mehrere) Zeichen zum Einlesen vorhanden, so wird das nächste Zeichen eingelesen und der Algorithmus beginnt von vorne.
Bei der nun folgenden Animation wird Text kodiert. Bei der Initialisierung des Lexikons werden zur Vereinfachung nur jene Einzelzeichen ins Lexikon eingetragen, die auch im Datenstrom vorkommen.
Als Ausgangsbasis für die Dekodierung erhält der Algorithmus einen Datenstrom und ein initialisiertes Lexikon (im Falle eines Textes wird das Lexikon mit 256 Einträgen initialisiert).
LZW verwendet bei der Dekodierung zwei Zwischenspeicher, diese werden als Buffer und Variable bezeichnet.
Der Datenstrom wird Zeichen für Zeichen eingelesen. Da das erste Zeichen immer im Lexikon vorhanden sein muss, wird dieser Vorgang außerhalb der Schleife durchgeführt, d.h. das Zeichen wird eingelesen und der "substring" des Zeichens in einer Variable gespeichert. Diese Variable wird dann ausgegeben und der Buffer wird der Variable gleichgesetzt.
Nun wird das nächste Zeichen eingelesen.
Befindet sich der Code des Inputs (eingelesenes Zeichen) bereits im Lexikon, so wird die Variable dem "substring" des Inputs gleichgesetzt. Ist der Code noch nicht im Lexikon vorhanden, handelt es sich um einen Sonderfall, der nicht besonders oft auftritt. In diesem Fall wird in die Variable der Buffer und das 1. Zeichen des Buffers geschrieben.
Die Variable wird nun ausgegeben und der Buffer plus das 1. Zeichen der Variable in das Lexikon geschrieben, d.h. das Lexikon wird um den Eintrag Buffer plus 1. Zeichen der Variable erweitert.
Abschließend wird der Buffer noch auf die Variable gesetzt und der Vorgang kann von vorne beginnen, sofern nicht das Ende des Datenstroms erreicht worden ist.
Bei der nun folgenden Animation wird der in der Animation im Kapitel "Kodierung" kodierte Datenstrom wieder dekodiert. Bei der Initialisierung des Lexikons werden zu Vereinfachung nur jene Einzelzeichen ins Lexikon eingetragen, die auch im dekodierten Datenstrom vorkommen.
Komprimierung von Text
Beim Komprimieren von Text werden die ersten 256 Einträge des Lexikons aus den 8-Bit-Werten des ASCII-Codes erstellt. Damit sind alle 1-Byte-Werte definiert und als Kodierung (= Code) vorhanden und können für die Komprimierung des Textes eingesetzt werden.
Komprimierung von Bildern
Bei der Komprimierung von Grafikdateien werden z.B. beim TIF-Format die Pixelinformationen in Bytes gepackt, bevor sie an den LZW-Algorithmus übergeben werden. Je nach Bittiefe des Bildes kann ein solches Byte einen kompletten Pixel, einen Teil eines Pixels oder mehrere Pixel repräsentieren.
Beim GIF-Format entspricht jeder LZW-Code einem kompletten Pixel. GIF unterstützt Bittiefen zwischen 1 und 8 Bit, sodass das Lexikon aus 2 bis 256 Basis-Einträgen bestehen muss.
Nähere Informationen zu den einzelnen Grafikdateiformaten findet man unter folgenden Links:
LZW kommt mit verschiedenen Bittiefen von 1 bis 24 Bit mindestens genauso gut zu Recht wie das Run-Length-Encoding-Verfahren, ist allerdings bei Bildern mit stark wechselnden Pixelwerten nicht sehr effektiv. Um jedoch die Kompressionsrate von Bildern mit stark wechselnden Pixelwerten zu verbessern, wird häufig die Methode der Differenzberechnung und Maßnahmen zur Rauschunterdrückung vor der Kompression angewendet.
Weitere Informationen zur Methode der Differenzberechnung findet man unter:
Methode der Differenzberechung