
 Verlauf
Verlauf


 Alle Kapitel anzeigen
Alle Kapitel anzeigen voriges Kapitel
voriges Kapitel
Prinzip eines Vocoders
Wenn man sich den Klang von bestimmten Synthesizern genauer anhört und ein wenig mit Filtern und Equalizern experimentiert, entstehen Geräusche, die Vokalen sehr ähnlich sind. Daraus kann man schließen, dass sich aus einem obertonreichen Signal Sprache erzeugen lässt. Wenn dies nun automatisch geschieht und nicht durch Drehen an Reglern, immer genau die richtigen Frequenzbänder beeinflusst werden und diese Information aus einem Sprachsignal gewonnen wird, dann handelt es sich um ein Vocoder-System.
Bei einem Vocoder gibt es nun keinen Equalizer, sondern Filterbänke. Das zu modulierende Eingangssignal (die menschliche Stimme) wird durch eine Reihe Bandpaßfilter geschickt und in Frequenzbänder zerlegt. Es wird sozusagen nachgesehen, welche Frequenzanteile im Signal enthalten sind. Man spricht hier vom Trägersignal oder Carrier. Modulationseingang, Filter und Envelope werden als Analyseteil bezeichnet.
Im Syntheseteil folgt auf das Filter ein VCA, der von der Steuerspannung aus dem Analyseteil gesteuert wird. Diese Kombination bildet einen Block, von dem meist mehrere in einem Vocoder vorkommen. Je nachdem wie viele Blöcke enthalten sind, verändert sich die Qualität des Vocoders. Meist sind ca. 15 Blöcke vorhanden, mit denen sich gute Sprachmodulationen erzielen lassen. Es sind aber auch Vocoder am Markt, die über bis zu 30 Blöcke verfügen – mehr Schaltkreise können aber auch schlechtere Qualität bedeutet, da es mehr „rauscht“.
Die Abbildung zeigt den schematischen Aufbau eines zwei-bandigen Vocoders.
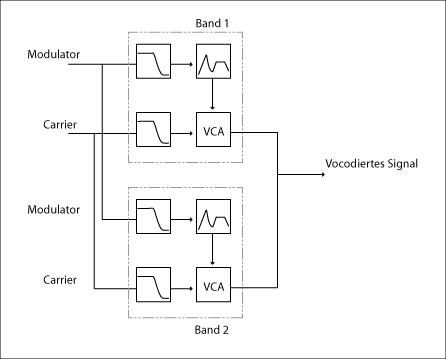
Abb.: schematischer Aufbau eines Vocoders mit zwei Bändern
Voiced/Unvoiced - Stimmhaft/Stimmlos
Die dargestellte Form der synthetischen Spracherzeugung funktioniert zwar für die Nachbildung von Vokalen (die stimmhaften Laute a, e, i, o, u), jedoch nicht für Konsonanten bzw. Zischlaute (die stimmlosen Laute z, sch, f, etc.). Somit muss im Syntheseteil des Vocoders noch eine weitere Aufgabe erledigt werden: Ein so genannter Voiced/Unvoiced Detector oder Stimmgenerator stellt fest, ob es sich um einen stimmlosen Laut handelt und mischt dem Ausgangssignal entweder hochfrequentes Rauschen, oder den Höhenanteil des originalen Sprachsignales bei.