
 Verlauf
Verlauf

 Alle Kapitel anzeigen
Alle Kapitel anzeigen
HTML steht für Hypertext Markup Language. Es handelt sich also um eine Auszeichnungssprache für Hypertext.
Die Wiedergabe von Information in traditionellen Medien wie Büchern, Zeitschriften etc. erfolgt üblicherweise als Text, also als lineare Abfolge von Wörtern, die auch in dieser Reihenfolge gelesen werden.
Hypertext ist die nicht-lineare Organisation und elektronische Wiedergabe von Informationen, die in zusammenhängenden Kontexten miteinander verlinkt sind. Ein Hypertext-Dokument kann man sich vorstellen als Buch, in dem Informationen in überschaubaren Blöcken dargestellt sind. Diese Blöcke enthalten Querverweise auf andere Blöcke, wodurch die Informationen zu einem Ganzen zusammengefügt werden. Während das Blättern zu Querverweisen in Büchern (wie etwa in einem Lexikon) eher die Konzentration stört, kann dieser Vorgang in einem elektronischen Hypertext-Dokument durch einen einzigen Mausklick erfolgen. Dies ermöglicht dem Leser die intuitive Navigation innerhalb eines Informationsangebots.
Zur einfachen und plattformunabhängigen Beschreibung von Hypertext wurde die Sprache HTML entwickelt. Mit HTML können Informationen (vor allem mit Links) strukturiert angegeben werden. Jeder grafische Browser besitzt einen sog. HTML-Parser, der die Beschreibung der Struktur interpretiert und die enthaltene Information entsprechend darstellt. So werden z. B. Links durch Unterstreichung gekennzeichnet.
Die Sprache HTML ist in etwa so alt wie das WWW, wurde also 1990 von Tim Berners-Lee am Genfer CERN-Institut aus der entwickelt. Das WWW und mit diesem auch HTML wurden aber erst mit aufkommen der ersten grafischen Browser populär. Diese Browser konnten - im Gegensatz zu früheren Browsern - den Inhalt einer Seite schon recht schön formatiert anzeigen und besaßen darüber hinaus die Möglichkeit Bilder oder andere grafische Elemente wie Buttons oder Textfelder anzuzeigen.
Mit dem Lauf der Zeit wurde HTML dann nach und nach weiter entwickelt und - meist durch den Antrieb der Browserhersteller - durch neue Techniken erweitert. Nach der ersten, damals noch wenig offiziellen, Version von HTML (1.0) folgte 1995 die zweite Version der Sprache (HTML 2.0) in der aber nur wenige Erneuerungen zu finden waren. Wiederum 2 Jahre später wurde 1997 nach langer Diskussion HTML 3.2 herausgegeben. Die Version 3.0 wurde einfach "übersprungen", da die einzelnen Parteien die an der Entwicklung teil hatten zu große Differenzen verband. So war die ursprüngliche HTML 3.0 Version weit von der damals aktuellen Browser-Realität entfernt und man überarbeitete schließlich den Entwurf erneut. 1998 wurde dann die vorerst letzte HTML-Version veröffentlicht. Darin wurde weniger auf neue Features hingearbeitet als mehr auf die Grundaufgaben von HTML. Dinge die in 3.2 eingeführt wurden, wurden wieder entfernt (bzw. als depracted bezeichnet, was bedeutet, dass es dieses Feature zwar noch gibt, es aber nicht verwendet werden sollte) und an andere Sprachen übergeben. So wurde z.B. das Formatieren von Texten wieder mehr an CSS herangebracht.
Der Nachfolger von HTML wird XHTML sein, eine sehr viel strengere Weiterentwicklung, die dadurch aber auch mehr Kompatibilität zu anderen Auszeichnungssprachen bringt. Für XHTML 1.0 gibt es bereits seit Jänner 2000 eine Empfehlung des W3-Konsortiums.
Grundgerüst eines HTML-Dokuments
Eine HTML-Datei besteht grundsätzlich aus drei Teilen.
Im ersten Teil wird der Dokumenttyp festgelegt:
Hier wird beispielsweise angegeben, dass es sich um ein HTML-Dokument in der Version 4.01 mit Erweiterungen handelt.
Der zweite Teil ist der Dateikopf, der innerhalb des Befehle definiert wird. Im HEAD werden der Titel des Dokumentes sowie eine Reihe weiterer Informationen definiert, die für den Nutzer in dieser Form nicht sichtbar sind:
Der dritte Teil ist der Dateikörper, welcher durch den Befehl definiert wird. Innerhalb des BODY werden alle sichtbaren Informationen (Bilder, Text, Videos etc.) definiert.
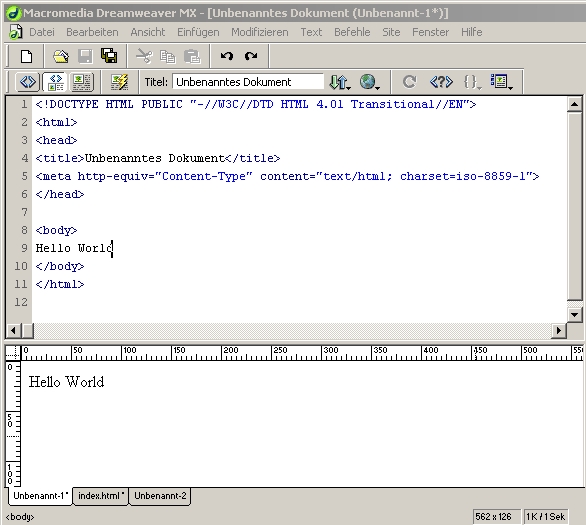
Hello World
HEAD und BODY werden durch den Befehl zu einer einheitlichen Datei zusammengefaßt. Eine einfache HTML-Seite, die nur den Text "Hello World" enthält sieht im Quellcode folgendermaßen aus:
Im HEAD werden also bestimmte Eigenschaften eines HTML-Dokuments festgelegt, die für den Benutzer nicht unmittelbar sichtbar sind. Neben dem Titel, z. B.
können noch eine Reihe von sog. Meta-Angaben gemacht werden, die die Webseite näher beschreiben oder Zusatz-Informationen für den Webserver liefern. Allgemeine Meta-Tags werden in der Form
<meta name="Eigenschaft" content="Wert">>
angegeben. Einige Beispiele dazu:
- <meta name="description" content="Wichtige Informationen für Web-Programmierer"> ... Kurzbeschreibung des Inhalts
- <meta name="author" content="Mickey Mouse"> ... Autor der Webseite
- <meta name="keywords" content="Preisvergleich Hardware Software Notebook PC"> ... Stichwörter für Suchmaschinen
- <meta name="date" content="2003-12-15T08:49:37+00:00"> ... Datum und Uhrzeit der Publikation der Seite
Informationen, die der Webserver verarbeiten soll, bekommen als Eigenschaft nicht "name", sondern "http-equiv":
- <meta http-equiv="content-type" content="text/html; charset=ISO-8859-1"> ... Angabe über den Standard-Zeichensatz, der im HTML-Dokument verwendet wurde
- <meta http-equiv="Content-Script-Type" content="text/javascript">> ... Angabe über die Standard-Scriptsprache
Es können aber auch echte Anweisungen für den Webserver sein:
- <meta http-equiv="expires" content="0"> ... Diese Seite wird auf jeden Fall vom Original-Server geladen und nicht aus dem Cache genommen.
- <meta http-equiv="refresh" content="3; URL=http://www.ufg.ac.at/"> ... bewirkt eine automatische Weiterleitung an die UfG-Homepage nach 3 Sekunden
- <meta http-equiv="pragma" content="no-cache"> ... weist den Proxy-Server an, keine Kopie von dieser Seite anzulegen.
Ausserdem können logische Verknüpfungen zu anderen Dokumenten hergestellt werden. Mit
<link rel="stylesheet" href="/css/general.css">
wird beispielsweise die Verbindung zu einer CSS-Datei hergestellt. Auch möglich wären Verbindungen zu Inhaltsverzeichnis, Stichwortverzeichnis, Anhang, Copyright, Hilfedatei etc., diese Angaben werden aber von den gängigen Web-Browsern nicht interpretiert. Darum wird fast nur die Angabe zu einer CSS-Datei verwendet.
Eine ausführliche Auseinandersetzung mit HTML-Seiten finden Sie auf den Seiten von Selfhtml.
