
 Verlauf
Verlauf


 Alle Kapitel anzeigen
Alle Kapitel anzeigen voriges Kapitel
voriges Kapitel
Ein Document wird mit PostScript beschrieben und sieht dann so aus:
%PDF−1.4
1 0 obj
<< /Type /Catalog
/Outlines 2 0 R
/Pages 3 0 R
>>
endobj
2 0 obj
<< /Type Outlines
/Count 0
>>
endobj
3 0 obj
<< /Type /Pages
/Kids [4 0 R]
/Count 1
>>
endobj
4 0 obj
<< /Type /Page
/Parent 3 0 R
/MediaBox [0 0 612 792]
/Contents 5 0 R
/Resources << /ProcSet 6 0 R >>
>>
endobj
5 0 obj
<< /Length 35 >>
stream
…Page-marking operators…
endstream
endobj
6 0 obj
[/PDF]
endobj
xref
0 7
0000000000 65535 f
0000000009 00000 n
0000000074 00000 n
0000000120 00000 n
0000000179 00000 n
0000000300 00000 n
0000000384 00000 n
trailer
<< /Size 7
/Root 1 0 R
>> startxref
408
%%EOF
Da PDF sehr mächtig ist, wird eine gewisse Struktur benötigt:
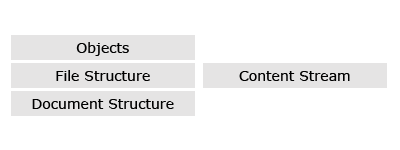
Objekte (Objects) sind
- Boolsche Werte
- Integer und reale Zahlen
- Strings
- Namen
- Listen
- Wörterbücher
- Streams
Objekte können einen Bezeichner zugewiesen bekommen und werden dann "Indirekte Objekte" genannt.
Die Dateistruktur (File Structure)
Enthält 4 Sektionen:
- Einen Header, der Auskunft über die PDF Version gibt.
- Eine Sektion Body, die die einzelnen Objekte enthält.
- Eine Objektzuordnungstabelle, die Informationen über die indirekten Objekte enthält
- Den Trailer, der die Adresse der Zuordnungstabelle und spezieller Objekte enthält
Die Dokumentstruktur (Document Structure)
verwaltet lediglich die einzelnen Seiten und die hierachische Struktur.
Content Streams
Ein PDF ist so aufgebaut, dass es gestreamt werden kann. Jede Seite kann als ein oder mehr Content Streams representiert werden. Nötig ist so ein Content Stream, da die Daten in einem PDF nach dem random-access Verfahren abgelegt sind und daher kein sequentieller Abruf möglich ist. Durch die Content Streams ist ein sequentieller Abruf möglich.
