
 Verlauf
Verlauf

 Alle Kapitel anzeigen
Alle Kapitel anzeigenGrundproblem abbildender Systeme
Sehen ist ein informationsverarbeitender Prozess, der aufgrund von optischen Reizen eine Beschreibung der Umwelt (re-)konstruiert. Dabei wird die dreidimensionale Umwelt über ein abbildendes System, wie das Auge, in zweidimensionale Verteilungen von Helligkeits- und Farbwerten abgeBILDet. Das Gehirn baut aus diesen zweidimensionalen Bildern wieder ein inneres Abbild der dreidimensionalen Umwelt auf.
Das Grundproblem abbildender Systeme besteht nun darin, dass jeder Punkt der Umwelt, der von einer Lichtquelle (direkt oder indirekt) angeleuchtet wird, Licht nach vielen Richtungen streut. Deshalb können wir einen Gegenstand aus verschiedenen Blickrichtungen wahrnehmen. Auf einen Bildpunkt einer zweidimensionalen Fläche treffen daher die Lichtstrahlen von vielen Punkten der Umwelt. Dadurch entsteht kein eindeutiges Abbild.
Ziel ist es daher, dass jeder Bildpunkt des zweidimensionalen Abbilds nur Licht von einem Objektpunkt empfängt, um eine eindeutige Information zu erhalten.
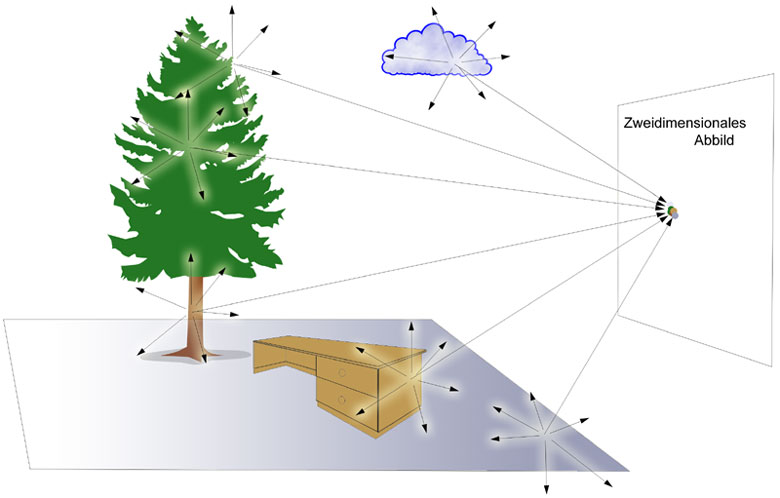
Abb.: Jeder Punkt der Umwelt, der von einer Lichtquelle (direkt oder indirekt) angeleuchtet wird, streut Licht nach vielen Richtungen aus. Auf einen Bildpunkt einer zweidimensionalen Fläche treffen daher die Lichtstrahlen von vielen Punkten der Umwelt. Es entsteht dadurch kein eindeutiges Abbild.
Deshalb erhält man kein brauchbares Abbild der Umwelt, wenn man einen Bogen Fotopapier einfach ins Licht hält. Man muss der zweidimensionalen Fläche ein System vorschalten, welches gewährleistet, dass im Idealfall zu einem Bildpunkt des Abbilds nur die Lichtstrahlen von einem Objektpunkt bzw. aus einer Raumrichtung gelangen. Im Laufe der Evolution wurden zwei Abbildungsprinzipien verwirklicht.
1. Kollimator
Kollimatoren sind Bündel von Röhren, die jeweils Licht aus einer ganz bestimmten Richtung durchlassen. Das durchgelassene Licht hängt vom Durchmesser und von der Länge der Röhren ab. Je länger und enger die Röhren sind, desto mehr störende Lichtstrahlen werden ausgeblendet und umso eindeutiger und präziser ist die Abbildung. Die Röhren können zueineinander parallel (Parallelprojektion) oder auf einer Kugeloberfläche (Zentralprojektion) angeordnet werden. Bei der Anordnung auf einer Kugeloberfläche ist die Größe des Blickfelds nicht eingeschränkt und kann theoretisch bis auf die vollständige Kugel ausgedehnt werden.
Die Augen der Insekten und Krebstiere sind Beispiele für Kollimatoren.
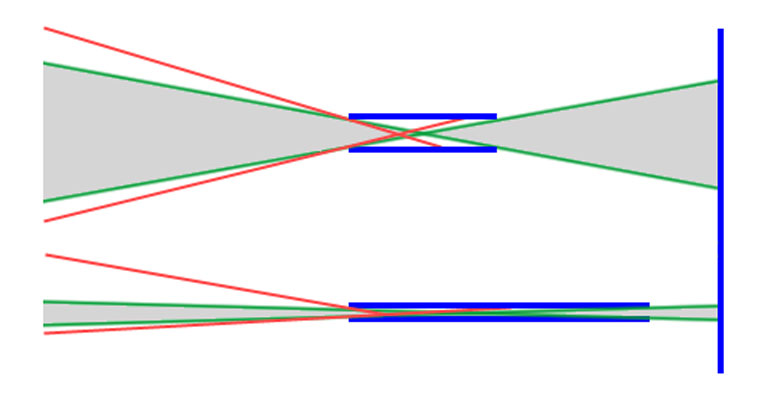
Abb.: Prinzip der Kollimatoren. Nur die Lichtstrahlen im grauen Breich werden vom Kollimator durchgelassen.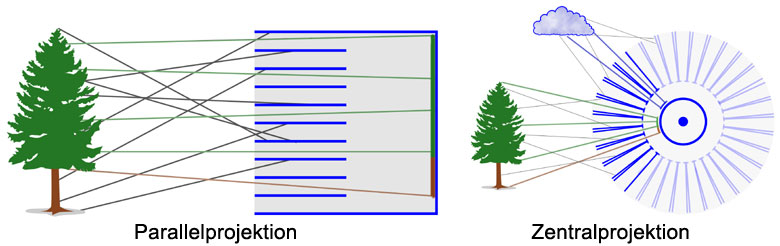
Abb.: Anordnung der Kollimatoren
2. Lochkamera
Bei einer Lochkamera werden die störenden Lichtstrahlen durch eine vorgeschaltete Blendenöffnung ausgeblendet. Ein Objektpunkt wird dabei als Kreisfläche auf der Bildebene abgebildet. Je kleiner die Blendenöffnung desto enger ist der Lichtkegel, der von einem Objektpunkt durch die Blendenöffnung auf die Bildebene projiziert wird und umso kleiner ist der Kreis, der den Objektpunkt abbildet.
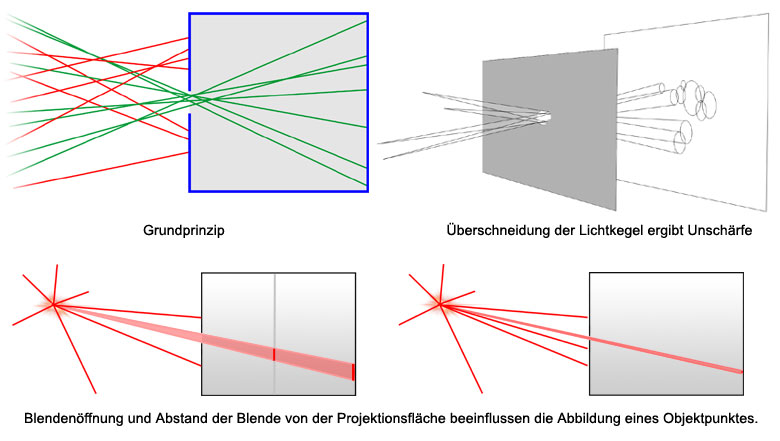
Abb.: Prinzip der Lochkamera
Durch die Überschneidung und Überlagerung der Projektionskreise werden mehrere benachbarte Objektpunkte auf einem Bildpunkt abgebildet. Daraus ergibt sich eine Unschärfe des Abbildes. Je kleiner die Blendenöffnung desto schärfer (= präziser, eindeutiger) das Abbild. Bei einer winzigen Blendenöffnung (z.B. Stecknadelloch) wird jeder Objektpunkt, egal wie weit er von der Blendenöffnung entfernt ist, gleich scharf abgebildet. Die Tiefenschärfe ist unendlich.
Die Größe des Blickfelds ist begrenzt und hängt vom Abstand der Blende von der Bildfläche ab.
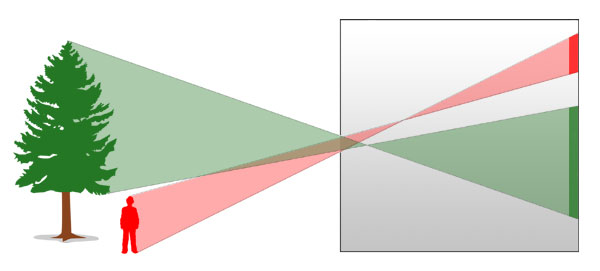
Abb.: Die Lochkamera erzeugt ein zentralperspektivisches Bild, das auf dem Kopf steht. (Der Unschärfebereich durch die Größe des Lochs wurde hier nicht eingezeichnet.)
Bei einer Lochkamera erhält man auf Grund der sehr kleinen Blendenöffnung lichtschwache Bilder. (Nebenbemerkung: Deshalb benötigt eine Lochkameraaufnahme in der Fotografie eine sehr lange Belichtungszeit, damit auf das lichtempfindliche Fotopapier genügend Licht auftrifft, um die notwendige Belichtung zu bewirken.)
Um dieses Problem zu lösen, kann man die Blendenöffnung vergrößern und in die Öffnung eine Sammellinse einsetzen, die die einfallenden Lichtstrahlen auf einen Bildpunkt bündelt. Durch die größere Öffnung fällt mehr Licht auf die Bildebene und die Bilder sind lichtstärker.
Dieses Prinzip ist z.B. bei den Linsenaugen der Wirbeltiere, beim Fotoapparat und bei Filmkamaras verwirklicht.
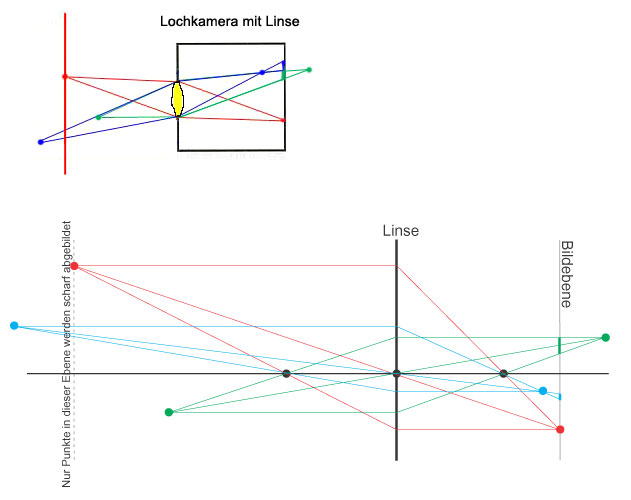
Abb.: Prinzip der Lochkamera mit Linse
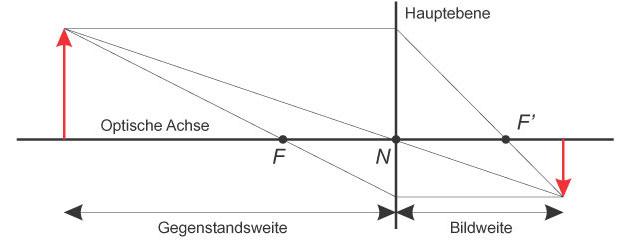
Abb.: Strahlengang für eine dünne Linse
F, F': objekt- und bildseitiger Brennpunkt, Abstand zwischen F und N: Brennweite
Bei einer Sammellinse werden jedoch nur die Punkte einer Ebene scharf abgebildet. Die restlichen Punkte sind unscharf – je weiter weg von dieser Ebene, desto unschärfer. Die Position der Ebene, die scharf abgebildet wird, kann über die Brennweite (= Wölbung) der Linse und den Abstand der Linse von der Bildebene verändert werden.
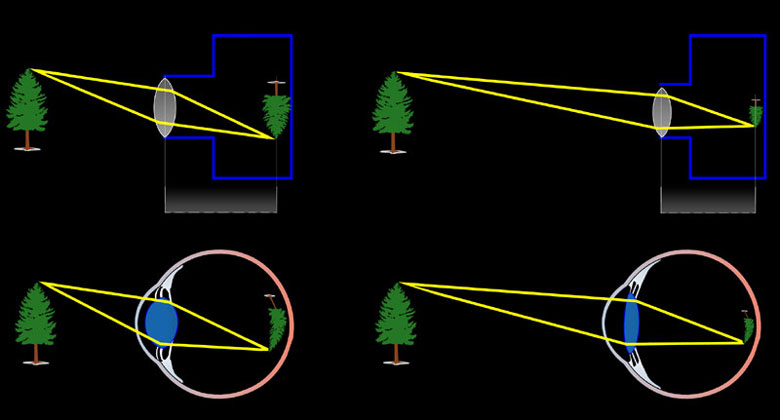
Beim Wirbeltierauge erfolgt das Scharfstellen auf eine bestimmte Entfernung (= Akkommodation) durch Veränderung der Linsenwölbung, im Fotoapparat durch Veränderung des Abstands der Linse von der Bildebene.
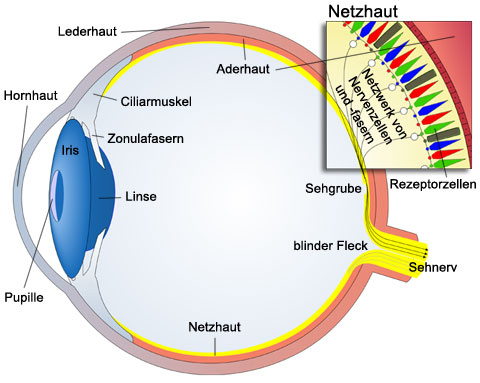
Das Auge ist kugelförmig und außen von der Lederhaut umschlossen, die im vorderen Teil in die durchsichtige vorgewölbte Hornhaut übergeht. An die Lederhaut schließt im Inneren die Aderhaut an, die die Blutgefäße zur Versorgung des Auges und vor allem der Netzhaut enthält und im vorderen Bereich in die Iris (Regenbogenhaut) übergeht. In der Mitte der Iris befindet sich die Pupille, die Öffnung durch die das Licht ins Innere des Auges gelangt. Diese Pupillenöffnung ist veränderbar. Hinter der Iris liegt der ringförmige Ciliarmuskel in dem über die nichtelastischen Zonulafasern die Linse aufgehängt ist. Die Innenwand des Auges ist mit der Netzhaut (Retina) ausgekleidet. Die Netzhaut ist in mehreren Schichten aufgebaut und enthält die lichtempfindlichen Rezeptorzellen, die über ein Netzwerk von Nervenzellen und -fasern mit dem Gehirn verbunden sind. Wo die gebündelten Nervenfasern (= Sehnerv) aus dem Auge austreten befindet sich der "blinde Fleck", da an dieser Stelle der Netzhaut keine Rezeptorzellen vorkommen. Ungefähr gegenüber der Pupillenöffnung liegt im Zentrum der Netzhaut die Sehgrube (Fovea). Das ist die lichtempfindlichste Stelle der Netzhaut.
Der Hohlraum zwischen Hornhaut und Iris ist mit Kammerwasser gefüllt. Das Innere des Auges ist mit einer durchsichtigen gallertartigen Masse, dem Glaskörper gefüllt, der von innen einen leichten Druck ausübt und dadurch dem Auge Stabilität gibt.
Der größte Anteil der Lichtbrechkraft des Auges und damit der Fokusierung (Lichtbündelung) kommt von der Vorderseite der Hornhaut, was auf die stark unterschiedlichen Brechungsindizes von Luft und Kammerwasser zurückzuführen ist. Daher können wir unter Wasser ohne Taucherbrille schlecht sehen, weil das Licht beim Übergang vom Wasser zum Kammerwasser kaum gebrochen wird.
Die Linse leistet nur einen kleinen Beitrag zur Lichtbrechung und ist vorallem für die Akkommodation, das Scharfstellen auf eine bestimmte Entfernung, wichtig.
Hornhaut und Linse haben auch eine Filterfunktion, denn sie halten 25 - 50 % des kurzwelligen einfallenden Lichtes unter 450 nm von der Netzhaut ab. Das ist zum einen ein Schutz gegen kurzwelliges Licht nahe am UV-Bereich und reduziert zum anderen das Problem der chromatischen Aberration.
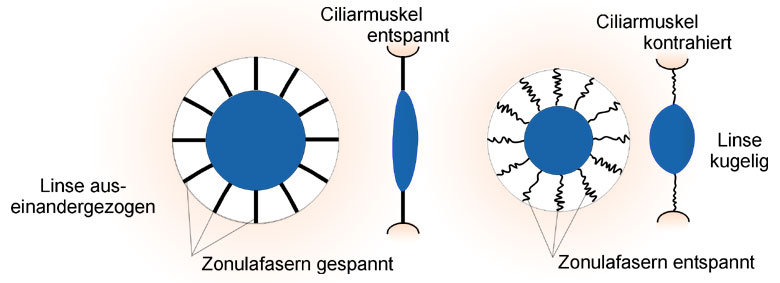
Abb.: Akkommodation
Wenn der Ciliarmuskel erschlafft ist, wird er durch den Augendruck auseinander gezogen, die Zonulafasern werden gespannt und ziehen die Linse auseinander, d.h. die Linse ist flach und das Auge ist fernakkommodiert, auf die Ferne scharf gestellt.
Wenn der Ciliarmuskel angespannt wird, zieht er sich zusammen, die Zonulafasern werden entspannt und die Linse baucht sich auf Grund ihrer eigenen Elastizität aus. Das einfallende Licht wird stärker gebrochen und das Auge ist nahakkommodiert, auf die Nähe scharf gestellt.
Netzhaut, Rezeptorzellen (Stäbchen und Zapfen)
Netzhaut
Die Netzhaut besteht aus mehreren Zellschichten. Die hinterste Schicht bilden die Rezeptorzellen (Stäbchen, Zapfen), die das auftreffende Licht in neuronale Signale umwandeln. Zwischen den Rezeptorzellen und den Ganglienzellen liegt ein Netzwerk von drei Neuronentypen (= Nervenzellen), den Horizontal-, Bipolar- und Amakrinzellen. Diese verbinden die Rezeptorzellen untereinander, sowie die Rezeptorzellen über diverse Verschaltungen mit den Ganglienzellen. In diesem Netzwerk findet durch komplexe Interaktionen eine Vorverarbeitung der Erregungswerte der einzelnen Rezeptoren statt. Die vorderste Schicht bilden die Ganglienzellen, die über die Bipolarzellen direkt sowie über das ganze Netzwerk indirekt mit den Rezeptorzellen in Verbindung stehen.
D.h. das einfallende Licht durchdringt zuerst die Schicht der Ganglienzellen und des Neuronennetzwerks bevor es auf die Rezeptorzellen trifft.
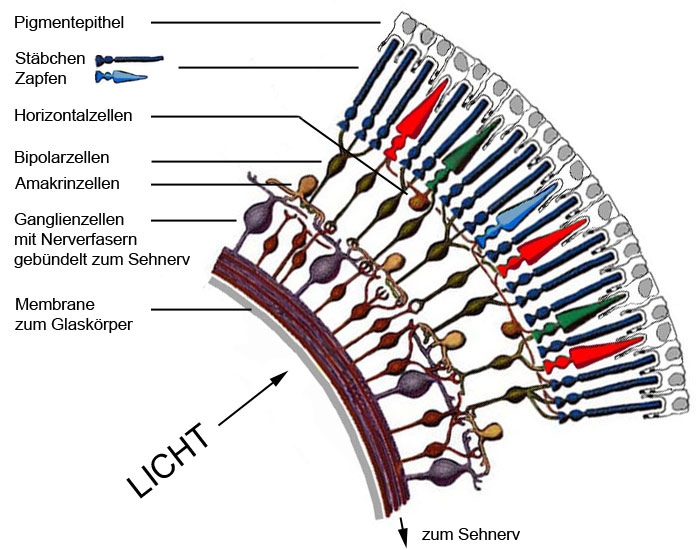
Abb.: Aufbau der Retina (Netzhaut).
Die Nervenfasern (Axione) der Ganglienzellen werden im Sehnerv gebündelt und sind die Verbindung zum Gehirn. Die Anzahl der Ganglienzellen in der Netzhaut beträgt ca. 1,5 Millionen. Das entspricht auch der Anzahl der Nervenfasern im Sehnerv und der Anzahl der Bildpunkte, die das Gehirn erreichen. Eine vergleichsweise geringe Anzahl, wenn man bedenkt dass bei den Digitalfotokameras eine Auflösung von 6 Millionen Pixel bereits Standard ist. Allerdings ist das Signal im Sehnerv bereits vorverarbeitet und das Signal jeder Nervenfaser enthält mehr Information als ein Pixel eines Digitalkamerabildes.
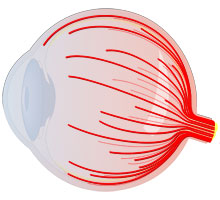
Abb.: Die Nervenfasern der Ganglienzellen überziehen die gesamte Netzhaut und werden im Sehnerv gebündelt.
Rezeptorzellen
Bei den Rezeptorzellen unterscheidet man zwischen zwei Typen, den Stäbchen und Zapfen, die wiederum in S-Zapfen, M-Zapfen und L-Zapfen unterteilt sind. Beide Typen haben im Wesentlichen dieselbe Struktur und enthalten ca. 10 Millionen lichtempfindliche Photopigmentmoleküle, die permanent neu gebildet werden. Jedes Photopigmentmolekül ist zusammengesetzt aus dem lichtempfindlichen Retinalmolekül (ähnlich dem Vitamin-A) und dem Protein Opsin. Werden die Retinalmoleküle von Lichtphotonen der richtigen Wellenlänge getroffen, erfolgt in der Netzhaut über einen mehrstufigen komplexen Vorgang die Umwandlung in einen Nervenimpuls. Dieser Umwandlungsprozess dauert ca. 50 Mikrosekunden (50 millionstel Sekunden).
Das Photopigmentmolekül der Stäbchen heißt Rhodopsin. Die Photopigmentmoleküle der Zapfen unterscheiden sich vom Rhodopsin und untereinander durch leicht veränderte Aminosäuresequenzen im Opsinteil. Dadurch ergibt sich die unterschiedliche Wellenlängenempfindlichkeit.
Stäbchen
Die Stäbchen sind "farbenblind" und können nur Lichtintensitäten verarbeiten. Mit ihnen ist nur eine Hell-Dunkelwahrnehmung (scoptopisches Sehen) möglich. Sie arbeiten bereits bei sehr geringen Beleuchtungsstärken (Dämmerungssehen). Die Gesamtanzahl der Stäbchen beträgt ca. 120 Millionen.
Zapfen
Die Zapfen ermöglichen Farbsehen und Hell-Dunkelwahrnehmung (photopisches Sehen). Weil es drei verschiedene Zapfentypen gibt, die unterschiedliche Empfindlichkeitsbereiche und -maxima innerhalb des sichtbaren Spektrums aufweisen, können aus der Kombination der drei Erregungsinformationen nicht nur wie bei den Stäbchen Lichtintensitäten unterschieden werden, sondern auch verschiedene Wellenlängen (= Farben). Die einzelnen Zapfentypen sind isoliert betrachtet wie die Stäbchen "farbenblind".
Die Zapfen benötigen eine relativ hohe Lichtstärke und sind bei Tageslicht wirksam. Sie brauchen etwa 30-fach höhere Lichtintensität als die Stäbchen. Die Gesamtanzahl der Zapfen beträgt ca. 6 Millionen.

Stäbchen (groß) und Zapfen (klein und gelb eingefärbt) in einer elektronenmikroskopischen Aufnahme der Retina eines Schwanzlurchs. Das Pigmentepithel ist abpräpariert.
(elektronenmikroskopische Aufnahme entnommen aus http://www.sinnesphysiologie.de/hvsinne/auge/rodcone.htm)
Empfindlichkeitsbereich der Stäbchen und Zapfen
Stäbchen werden optimal von blau-grünem Licht (mit einer Wellenlänge von ca. 500 nm) angeregt und vermitteln die Wahrnehmung von Grautönen.
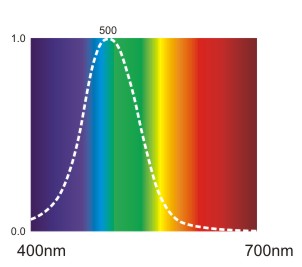
Abb.: Normalisierte Sensitivitätskurve der Stäbchen.
Die Kurve ist eine normalisierte Darstellung, die für jede Wellenlänge die Sensitivität der Stäbchen angibt. Dabei wird die maximale Sensitivität, die bei 500 nm liegt, mit 100% oder 1.0 angenommen und relativ dazu werden die Erregungswerte bei anderen Wellenlängen in Prozent ausgedrückt. Für die Erstellung der Kurve ist es natürlich wichtig, dass für jede Wellenlänge Licht derselben Intensität auf die Stäbchen trifft. Licht, das nur aus einer Wellenlänge "aufgebaut" ist, nennt man monochromatisches Licht.
Zapfen dagegen teilen sich das Spektrum in drei Bereiche auf: Das Absorptionsmaximum der S-Zapfen (short wavelength) oder Blauzapfen liegt bei ca. 420 nm, das der M-Zapfen (medium wavelenght) oder Grünzapfen bei ca. 540 nm und das der L-Zapfen (long wavelength) oder Rotzapfen bei ca. 560 nm (wobei eigentlich das Empfindungsmaximum der Rotzapfen im gelben Bereich liegt). [Die nm-Werte schwanken leicht in der Literatur.]
Die Information, welche Zapfenart wie stark angeregt wird, ist die Ausgangsbasis für einen komplexen Informationsverarbeitungsprozess in der Retina und im Gehirn, der in einer Farbempfindung mündet.
In der nachstehenden Abbildung erkennt man, dass die S-Zapfen nur auf Licht von violett bis gelbgrün, die M- und L-Zapfen jedoch auf Licht aus dem gesamten Spektrum reagieren. Die M- und L-Zapfen haben sehr ähnliche Empfindungskurven, da sich ihre Photopigmentmoleküle kaum unterscheiden. Die L-Zapfen werden im Rotbereich stärker angeregt .
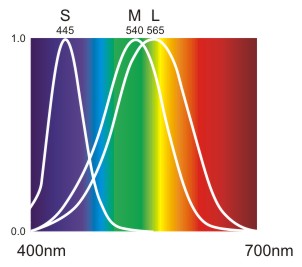
Abb.: Normalisierte Absorptionskurven (Sensitivitätskurven) der drei Zapfentypen.
Diese Kurven liefern die relative Erregung der Rezeptoren bei einfallendem Licht einer bestimmten Wellenlänge. D.h. man isoliert die Rezeptoren, setzt sie dem Licht einer bestimmten Wellenlänge aus und misst die Erregung. So erhält man die Erregungswerte für jede Wellenlänge, wobei wichtig ist, dass für jede Wellenlänge dieselbe Lichtintensität verwendet wurde. Dem höchsten Erregungswert wird 100% bzw. 1.0 (= Empfindungsmaximum) und allen anderen Wellenlängen werden die entsprechenden Prozentwerte zugeordnet.
Zu beachten ist, dass diese Kurven keinen Vergleich der absoluten Empfindlichkeit der drei Zapfentypen bieten. Für einen Vergleich ist es wichtig, dass es gemessen an der Gesamtzahl der Zapfen 63% L-Zapfen, 31% M-Zapfen und nur 6% S-Zapfen gibt. Daraus ergibt sich nachstehendes vergleichendes Kurvenbild.
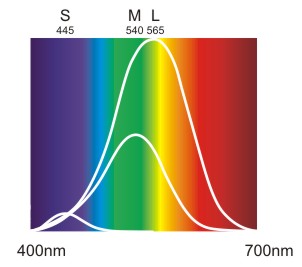
Abb.: Normalisierte Absorptionskurven der drei Zapfentypen gewichtet nach der prozentuellen Verteilung.
Es gibt ungefähr doppelt soviele L-Zapfen wie M-Zapfen und fünf mal mehr M-Zapfen als S-Zapfen. Daher ist das Maximum der L-Kurve doppelt so hoch wie bei der M-Kurve und deren Maximum fünf mal höher als bei der S-Kurve.
Diese Kurven sagen jedoch nichts darüber aus, wie die Informationen von den Zapfen weiterverarbeitet werden. Denn tatsächlich kommt den Informationen von den S-Zapfen wesentlich mehr Bedeutung zu als es in dieser Abbildung zu vermuten wäre.
Verteilung von Stäbchen und Zapfen auf der Netzhaut
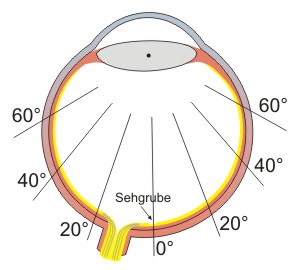
Abb.: In Texten liest man von Gradangaben, wenn Bereiche der Netzhaut beschrieben werden. 0° steht dabei für die Sehachse von der Linse zum Zentrum der Sehgrube.
Die Stäbchen und einzelnen Zapfentypen sind auf der Netzhaut sehr unterschiedlich verteilt.
Die Sehgrube (Fovea, ca. 1 mm) enthält nur schlanke Zapfen in einer sehr dichten regelmäßigen hexagonalen Anordnung. Im Zentrum der Sehgrube (Foveola) gibt es nur M- und L-Zapfen (bis zu 250.000 pro mm²), die zum Sehgrubenrand auf 50.000 pro mm² und weiter zum Rand der Netzhaut auf 5.000 pro mm² abnehmen. Die S-Zapfen, die im Zentrum der Sehgrube vollkommen fehlen, haben ihre größte Dichte am Sehgrubenrand (bei 1°) mit 2.000 pro mm² und nehmen zum Rand der Netzhaut auf 500 pro mm² ab.
Jeder Rezeptorzelle in der Sehgrube ist eine Ganglienzelle zugeordnet. Dadurch wird eine hohe Auflösung erreicht. Die Sehgrube ist somit der Bereich des schärfsten Sehens auf der Netzhaut. Ein Gegenstand, welcher vom Betrachter fixiert wird, wird immer so abgebildet, dass dessen Abbild genau in der Sehgrube, dem Bereich des schärfsten Sehens liegt. Ungefähr die Hälfte aller Zapfen ist im Bereich der Sehgrube angeordnet.
Da durch die geringe Dichte der peripheren Zapfen und der Krümmung der Netzhaut kein scharfes Bild möglich ist, dienen die Zapfen in den Außenbereichen der Netzhaut für die Wahrnehmung von Bewegung, Helligkeit und Farbkontrast. Wir können am Rand unseres Gesichtsfeldes (im Augenwinkel) zwar Bewegungen, aber keine genauen Formen wahrnehmen.
Die Stäbchen, die in der Sehgrube nicht vorhanden sind, haben ihre größte Dichte von ca. 150.000 pro mm² in einem Ring um die Sehgrube (bei 17°) und nehmen zum Netzhautrand auf 80.000 pro mm° ab. Daher darf man im Dämmerlicht einen Gegenstand nicht fixieren (in der Sehgrube sind keine Stäbchen), sondern muss den Blick neben dem Gegenstand ausrichten, damit dieser auf dem Stäbchenring abgebildet wird.
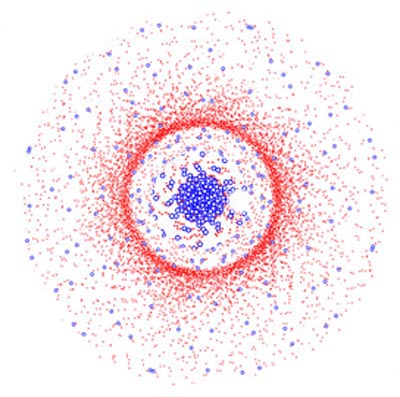
Abb.: Schematische Darstellung der Verteilung von Zapfen (blaue Kreise) und Stäbchen (rote Punkte) auf der Netzhaut. Man erkennt deutlich die Zapfendichte in der Sehgrube und den Stäbchenring.
Rechts von der Sehgrube ist der weiße Kreis des blinden Flecks zu erkennen, wo keine Rezeptorzellen liegen können.
Verarbeitung der Rezeptorinformationen, Farbwahrnehmung, Gegenfarben
Die Absorptionskurven der Zapfen zeigen wie die einzelnen Zapfentypen auf Licht bestimmter Wellenlänge reagieren. Aber sie beschreiben nicht, wie der Output der Zapfen weiterverarbeitet wird um beim Betrachter einen bestimmten Eindruck von Helligkeit und Farbe hervorzurufen.
Ein Zapfen wird in demselben Ausmaß stärker angeregt, wenn die Intensität (= Helligkeit) des einfallenden Lichts zunimmt (d.h. mehr Photonen treffen auf den Zapfen) oder wenn sich die Wellenlängen des einfallenden Lichts in Richtung des Maximums der Sensitivitätskurve verschieben (= Farbveränderung). D.h. ein einzelner Zapfen kann nicht zwischen Farb- oder Helligkeitsveränderungen unterscheiden. Somit kann ein Zapfen nicht signalisieren von welchen Wellenlängen er angeregt wurde.
Erst wenn der Output von mindestens zwei Zapfentypen kombiniert wird, kann man zwischen Farbe und Helligkeit unterscheiden. Voraussetzung dafür ist jedoch, dass sich die Absorptionskurven der Zapfentypen überschneiden und der Output eines Zapfentyps nicht durch den anderen Typ beeinflusst wird, d.h. dass sie unabhängig reagieren. Wenn diese Voraussetzungen erfüllt sind, kann mann durch Addition und Subtraktion der Erregungswerte Helligkeit und Farbe unterscheiden.
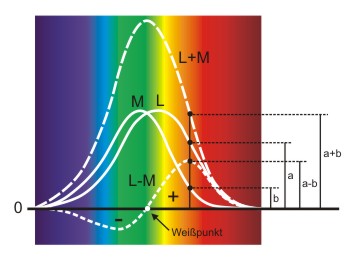
Abb.: Addition und Subtraktion der M- und L-Absorptionskurven. An einem Punkt wird gezeigt wie die Ergebniskurven aus den Ausgangskurven ermittelt werden.
Wenn man das Maximum wieder mit 100% gleichsetzt ist die Kurve L-M die normalisierte Sensitivitätskurve des Zweizapfensystems, sozusagen ein "Superzapfen". Die Werte von L-M können sowohl positiv als auch negativ sein. Dadurch wird der Spektralbereich eindeutig in zwei unterscheidbare Farbbereiche aufgeteilt. Diese Gegenfarbbereiche (+/-) haben in diesem Fall ihre Maxima im Grün- bzw. Rotbereich. Beim Weißpunkt werden die beiden Zapfentypen mit der gleichen Intensität angeregt.
Wenn nur die Intensität des einfallenden Lichts zunimmt, bleibt der Wert von L-M gleich, da die Erregung bei beiden Zapfen um den gleichen Anteil zunimmt. Das System erkennt daher, dass nur die Helligkeit zugenommen hat. Ändert sich jedoch die Wellenlänge, so kommt es zu einer Veränderung des Wertes von L-M und das System erkennt eine Farbverschiebung. Somit sind Helligkeits- und Farbveränderungen unterscheidbar.
Zone theory, Gegenfarben
Man geht nun davon aus, dass im Netzwerk der Retina durch derartige "Berechnungen" die Rohdaten der L-, M- und S-Zapfen in zwei unabhängige Farbwerte und ein Helligkeitssignal transformiert werden, wobei die resultierenden Farbsignale in Zusammenhang mit den Gegenfarben, die in der Farbwahrnehmung eine wichtige Rollen spielen, stehen. Denn es ist z.B. möglich, zu Rot ein Gelb oder zu Blau ein Rot zu mischen und es entsteht dabei der Eindruck von einem gelblichen Rot oder einem rötlichen Blau. Wenn wir aber zu Rot ein Grün oder zu Blau ein Gelb mischen, haben wir nicht den Eindruck von einem grünlichen Rot oder gelblichen Blau. Rot - Grün und Blau - Gelb empfinden wir als Gegenfarbpaare. Auch beim Phänomen der Nachbilder, des Simultankontrasts oder bei bestimmten Formen der Farbenblindheit stoßen wir auf die Gegenfarben.
Wenn man die Gegenfarbpaare als Koordinatenachsen auffasst, dann liegt jede Farbe in einem der vier Quadranten und wird durch zwei Farbwerte (je einer pro Gegenfarbpaar) und deren Verhältnis zueinander charakterisiert. Dadurch wird, ergänzt durch das Helligkeitssignal, ein "Farbraum" aufgespannt, der die Unterscheidung der einzelnene Farbtöne ermöglicht.
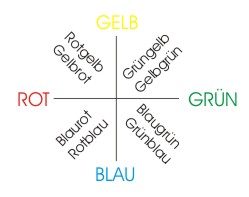
Abb.: Gegenfarbpaare.
Man nimmt nun an, dass die Transformation der Rohdaten der L-, M- und S-Zapfen durch folgende Regeln geschieht :
(Wobei "Addition" und "Subtraktion" hier nur prinzipiell zu verstehen sind. Die eigentlichen Berechnungen sind durch Faktoren gewichtet.)
- Die Addition der Outputs von L, M und S "L+M+S" wird als Helligkeit interpretiert. Die Kurve entspricht auch annähernd der Absorptionskurven der Stäbchen.
- Die Differenz von M-Output und dem addierten L- und S-Output "L-M+S" liefert die Gegenfarbenbereiche Rot und Grün und ermöglicht die Rot- und Grün-Unterscheidung.
- Die Differenz von S-Output und dem addierten L- und M-Output "L+M-S" liefert die Gegenfarbenbereiche Blau und Gelb und ermöglicht die Blau- und Gelb-Unterscheidung.
Wenn der L- und M-Output annähernd gleich und im Vergleich zum S-Output hoch sind, sehen wir Farben aus dem Gelbbereich.
Wenn L- und S-Output im Vergleich zum M-Output hoch ist, dann sehen wir die Farben, die nicht im Spektrum vorkommen: Blauviolett, Purpur, Rotviolett.
Wenn L-, M- und S-Output annähernd gleich sind, sehen wir Weiß, Grau oder Schwarz in Abhängigkeit von der Lichtintensität. Wobei Grau nur bei Körperfarben wahrgenommen wird. Wir sehen kein graues, sondern nur ein schwaches weißes Licht.
Empirische Farbvergleichsversuche haben gezeigt, dass sich ausgehend von den vier ausgewählten "elementaren" Farben (Blau, Grün, Gelb und Rot), die zu zwei Gegenfarbpaaren zusammengefasst werden, alle monochromen Farben aus zwei "elementaren" Farben mischen lassen. Aus diesen Versuchen wurden nachstehende Kurven abgeleitet, die das Mischungsverhältnis der zwei Farben angeben.
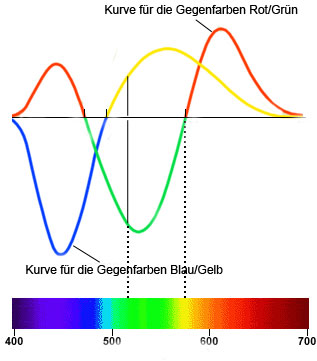
Abb.: Gegenfarbenkurven. Je nachdem, ob eine Kurve über oder unter der Nullachse liegt, wird die eine oder andere Farbe aus dem Gegenfarbenpaar für die Mischung verwendet.
Interessant ist, dass sich diese Kurven aus den Rohdaten der L-, M- und S-Zapfen durch die oben angeführten Transformationen ableiten lassen.
Die Kurve für das Gegenfarbenpaar Rot/Grün ergibt sich aus 2.4*L - 5.7*M + 3.8*S und die Kurve für das Gegenfarbenpaar Blau/Gelb aus 0.36*L + 0,72*M - 7.6*S
![]()
Abb. entnommen aus http://handprint.com/HP/WCL/color2.html
Es ist daher naheliegend, dass für die Farbwahrnehmung derartige Transformationen des Zapfenoutputs erfolgen und sich dort, wo die Kurven die Nullachse schneiden, Farben ergeben, die als Bezugspunkte für die Farbwahrnehmung dienen. D.h. diese speziellen Farben ergeben sich aus den Transformationen und sind nicht vorgegeben. Die Transformationen haben sich in einem evolutionären Prozess entwickelt, um das Auge möglichst optimal an die Umweltbedingungen anzupassen.
Zusammengefasst noch einmal der Weg vom Zapfenoutput über die Transformationen im Netzwerk der Retina bis zum Aufbau der Gegenfarbpaare und Helligkeitskomponente, sowie der Einordnung eines Farbtons in dieses System.
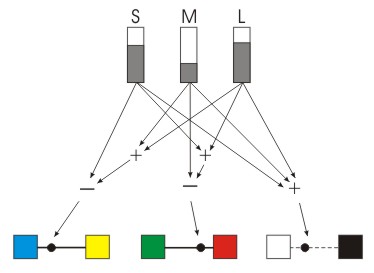
Abb.: Schematische, vereinfachte Darstellung der Zone
Das Farbmodell CIELab beruht ebenfalls auf zwei Gegenfarbpaaren (a+ und a- bzw. b+ und b-) und einer Helligkeitsdimension L.